Scikit aprende Validación cruzada [Guía útil]
En este tutorial de Python, aprenderemos cómo funciona la validación cruzada de aprendizaje de Scikit en Python y también cubriremos diferentes ejemplos relacionados con la validación cruzada de aprendizaje de Scikit. Además, cubriremos estos temas.
SCIKIT APRENDE VALIDACIÓN CRUZADA
En esta sección, aprenderemos sobre los trabajos de validación cruzada de Scikit en python.
La validación cruzada se define como un proceso en el que entrenamos nuestro modelo usando un conjunto de datos y luego evaluamos usando un conjunto de datos de apoyo.
Código:
En el siguiente código, importaremos algunas bibliotecas desde las que entrenamos nuestro modelo y también lo evaluaremos.
- x, y = datasets.load_iris(return_X_y=True) se usa para cargar el conjunto de datos.
- x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.4, random_state=0) se usa para dividir el conjunto de datos en datos de entrenamiento y datos de prueba.
- x_train.shape, y_train.shape se utiliza para evaluar la forma del modelo de tren.
- classifier = svm.SVC(kernel=’linear’, C=1).fit(x_train, y_train) se usa para ajustar el modelo.
- puntuaciones = cross_val_score(clasificador, x, y, cv=7) se utiliza para calcular la puntuación del valor cruzado.
import numpy as num
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn import svm
x, y = datasets.load_iris(return_X_y=True)
x.shape, y.shape
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.4, random_state=0)
x_train.shape, y_train.shape
x_test.shape, y_test.shape
classifier = svm.SVC(kernel="linear", C=1).fit(x_train, y_train)
classifier.score(x_test, y_test)
from sklearn.model_selection import cross_val_score
classifier = svm.SVC(kernel="linear", C=1, random_state=42)
scores = cross_val_score(classifier, x, y, cv=7)Producción:
Después de ejecutar el código anterior, obtenemos el siguiente resultado en el que podemos ver que la puntuación de las métricas de validación cruzada en forma de matriz se imprime en la pantalla.Scikit aprende validación cruzada
PUNTAJE DE VALIDACIÓN CRUZADA DE APRENDIZAJE DE SCIKIT
En esta sección, aprenderemos cómo funciona Scikit Learn Cross-Validation Score en python.
Las puntuaciones de validación cruzada se definen como el proceso para estimar la capacidad del modelo de nuevos datos y calcular la puntuación de los datos.
Código:
En el siguiente código, importaremos algunas bibliotecas a partir de las cuales podemos calcular la puntuación de validación cruzada.
- diabetes = datasets.load_diabetes() se utiliza para cargar los datos.
- x = diabetes.data[:170] se utiliza para calcular los datos de diabetes.
- print(cross_val_score(lasso, x, y, cv=5)) se utiliza para imprimir la puntuación en la pantalla.
from sklearn import datasets, linear_model
from sklearn.model_selection import cross_val_score
diabetes = datasets.load_diabetes()
x = diabetes.data[:170]
y = diabetes.target[:170]
lasso = linear_model.Lasso()
print(cross_val_score(lasso, x, y, cv=5))Producción:
Después de ejecutar el código anterior, obtenemos el siguiente resultado en el que podemos ver que la puntuación de validación cruzada se imprime en la pantalla.
Puntaje de validación cruzada de aprendizaje de Scikit
SCIKIT APRENDE LAZO DE VALIDACIÓN CRUZADA
En esta sección, aprenderemos cómo funciona Scikit Learn Cross-Validation Lasso en Python.
Lasso significa contracción mínima absoluta y operador selector que se utiliza para determinar el peso del término de penalización.
Código:
En el siguiente código, importaremos algunas bibliotecas desde las que podemos calcular la puntuación de lazo de validación cruzada.
- x, y = make_regression(noise=5, random_state=0) se usa para hacer o generar la regresión.
- regresión = LassoCV(cv=7, random_state=0).fit(x, y) se usa para ajustar el modelo de lazo.
- regression.score(x, y) se utiliza para calcular la puntuación de lazo.
from sklearn.linear_model import LassoCV
from sklearn.datasets import make_regression
x, y = make_regression(noise=5, random_state=0)
regression = LassoCV(cv=7, random_state=0).fit(x, y)
regression.score(x, y)Producción:
En el siguiente resultado, podemos ver que se calcula la puntuación de lazo y el resultado se imprime en la pantalla.
 Scikit aprende puntuación de lazo de validación cruzada
Scikit aprende puntuación de lazo de validación cruzada
SCIKIT APRENDER PREDICCIÓN DE VALIDACIÓN CRUZADA
En esta sección, aprenderemos cómo Scikit aprende el trabajo de predicción de validación cruzada en python.
- El método de predicción de validación cruzada de aprendizaje de Scikit se utiliza para predecir el error visualizándolo.
- La validación cruzada se utiliza para evaluar los datos y también utiliza diferentes partes de los datos para entrenar y probar el modelo.
Código:
En el siguiente código, importaremos algunas bibliotecas desde las que podemos evaluar la predicción a través de la validación cruzada.
- x, y = datasets.load_diabetes(return_X_y=True) se utiliza para cargar el conjunto de datos.
- predict = cross_val_predict(linearmodel,x, y, cv=10) se usa para predecir el modelo y devolver una matriz del mismo tamaño.
- fig, axis = plot.subplots() se usa para trazar la figura en la pantalla.
- axis.scatter(y, predict, edgecolors=(0, 0, 0)) se usa para trazar el gráfico de dispersión en el gráfico.
- axis.plot([y.min(), y.max()], [y.min(), y.max()], “b–“, lw=6) se utiliza para trazar el eje en el gráfico .
- axis.set_xlabel(“Medido”) se utiliza para trazar la etiqueta x en el gráfico.
- axis.set_ylabel(“Predicted”) se utiliza para trazar la etiqueta y en el gráfico.
from sklearn import datasets
from sklearn.model_selection import cross_val_predict
from sklearn import linear_model
import matplotlib.pyplot as plot
linearmodel = linear_model.LinearRegression()
x, y = datasets.load_diabetes(return_X_y=True)
predict = cross_val_predict(linearmodel,x, y, cv=10)
fig, axis = plot.subplots()
axis.scatter(y, predict, edgecolors=(0, 0, 0))
axis.plot([y.min(), y.max()], [y.min(), y.max()], "b--", lw=6)
axis.set_xlabel("Measured")
axis.set_ylabel("Predicted")
plot.show()Producción:
Después de ejecutar el código anterior, obtenemos el siguiente resultado en el que podemos ver que el gráfico se traza en la pantalla con una predicción de validación cruzada.
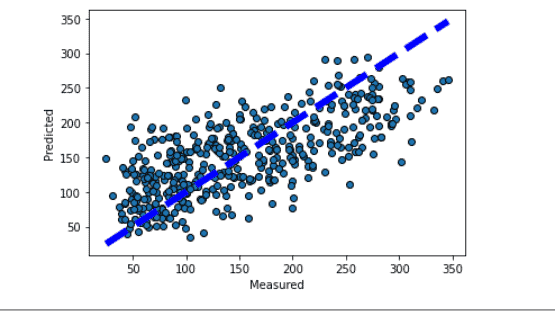 scikit aprender validación cruzada predecir
scikit aprender validación cruzada predecir
SCIKIT APRENDE SERIES DE TIEMPO DE VALIDACIÓN CRUZADA
En esta sección, aprenderemos cómo Scikit aprende el trabajo de las series temporales de validación cruzada en python.
- La serie de tiempo de validación cruzada de aprendizaje de Scikit se define como una serie de conjuntos de prueba que consisten en una sola observación.
- El conjunto de entrenamiento consiste solo en la observación que se combina antes en el tiempo con la observación que forma el conjunto de prueba.
- En la validación cruzada de series de tiempo, no se considera ninguna observación futura al construir el pronóstico.
Código:
En el siguiente código, importaremos algunas bibliotecas desde las que podemos ver cómo se pueden dividir los datos a través de series temporales.
- x = num.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]]) se usa para dar el valor a la x
- y = num.array([1, 2, 3, 4, 5, 6]) se usa para dar el valor a y.
- print(timeseriescv) se utiliza para imprimir los datos de validación cruzada de series temporales.
- x = num.random.randn(12, 2) se usa para fijar el tamaño de la prueba a 2 con 12 muestras.
- print(“TREN:”, train_index, “TEST:”, test_index) se utiliza para imprimir los datos del tren y de la prueba.
import numpy as num
from sklearn.model_selection import TimeSeriesSplit
x = num.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]])
y = num.array([1, 2, 3, 4, 5, 6])
timeseriescv = TimeSeriesSplit()
print(timeseriescv)
for train_index, test_index in timeseriescv.split(x):
print("TRAIN:", train_index, "TEST:", test_index)
x_train, x_test = x[train_index], x[test_index]
y_train, y_test = y[train_index], y[test_index]
x = num.random.randn(12, 2)
y = num.random.randint(0, 2, 12)
timeseriescv = TimeSeriesSplit(n_splits=3, test_size=2)
for train_index, test_index in tscv.split(x):
print("TRAIN:", train_index, "TEST:", test_index)
x_train, x_test = x[train_index], x[test_index]
y_train, y_test = y[train_index], y[test_index]Producción:
En el siguiente resultado, podemos ver que los datos del tren y de la prueba se dividen con la validación cruzada de la serie temporal.
 Scikit aprende series de tiempo de validación cruzada
Scikit aprende series de tiempo de validación cruzada
SCIKIT APRENDE DIVISIÓN DE VALIDACIÓN CRUZADA
En esta sección, aprenderemos cómo Scikit aprende la división de validación cruzada en python.
- La validación cruzada se define como un proceso que se utiliza para evaluar el modelo en muestras de datos finitos.
- Los datos de validación cruzada se pueden dividir en varios grupos con un solo parámetro llamado K.
Código:
En el siguiente código, importaremos algunas bibliotecas desde las cuales el modelo se puede dividir en varios grupos.
- num.random.seed(1338) se utiliza para generar números aleatorios.
- n_splits = 6 se utiliza para dividir los datos.
- percentiles_classes = [0.1, 0.3, 0.6] se utiliza para generar los datos de la clase.
- groups = num.hstack([[ii] * 10 for ii in range(10)]) se usa para dividir el grupo en partes iguales
- fig, axis = plot.subplots() se usa para trazar la figura.
- axis.scatter() se usa para trazar el diagrama de dispersión.
- axis.set_title(“{}”.format(type(cv).__name__), fontsize=15) se usa para dar el título al gráfico.
from sklearn.model_selection import (
TimeSeriesSplit,
KFold,
ShuffleSplit,
StratifiedKFold,
GroupShuffleSplit,
GroupKFold,
StratifiedShuffleSplit,
StratifiedGroupKFold,
)
import numpy as num
import matplotlib.pyplot as plot
from matplotlib.patches import Patch
num.random.seed(1338)
cmapdata = plot.cm.Paired
cmapcv = plot.cm.coolwarm
n_splits = 6
n_points = 100
x = num.random.randn(100, 10)
percentiles_classes = [0.1, 0.3, 0.6]
y = num.hstack([[ii] * int(100 * perc) for ii, perc in enumerate(percentiles_classes)])
groups = num.hstack([[ii] * 10 for ii in range(10)])
def visualize_groups(classes, groups, name):
# Visualize dataset groups
fig, axis = plot.subplots()
axis.scatter(
range(len(groups)),
[0.5] * len(groups),
c=groups,
marker="_",
lw=50,
cmap=cmapdata,
)
axis.scatter(
range(len(groups)),
[3.5] * len(groups),
c=classes,
marker="_",
lw=50,
cmap=cmapdata,
)
axis.set(
ylim=[-1, 5],
yticks=[0.5, 3.5],
yticklabels=["Data\ngroup", "Data\nclass"],
xlabel="Sample index",
)
visualize_groups(y, groups, "nogroups")
def plot_cv_indices(cv, x, y, group, ax, n_splits, lw=10):
"""Create a sample plot for indices of a cross-validation object."""
# Generate the training/testing visualizations for each CV split
for ii, (tr, tt) in enumerate(cv.split(X=x, y=y, groups=group)):
# Fill in indices with the training/test groups
indices = np.array([np.nan] * len(x))
indices[tt] = 1
indices[tr] = 0
# Visualize the results
axis.scatter(
range(len(indices)),
[ii + 0.5] * len(indices),
c=indices,
marker="_",
lw=lw,
cmap=cmapcv,
vmin=-0.2,
vmax=1.2,
)
axis.scatter(
range(len(x)), [ii + 1.5] * len(x), c=y, marker="_", lw=lw, cmap=cmapdata
)
axis.scatter(
range(len(x)), [ii + 2.5] * len(x), c=group, marker="_", lw=lw, cmap=cmapdata
)
# Formatting
yticklabels = list(range(n_splits)) + ["class", "group"]
axis.set(
yticks=np.arange(n_splits + 2) + 0.5,
yticklabels=yticklabels,
xlabel="Sample index",
ylabel="CV iteration",
ylim=[n_splits + 2.2, -0.2],
xlim=[0, 100],
)
axis.set_title("{}".format(type(cv).__name__), fontsize=15)
return axis
fig, axis = plot.subplots()
cv = KFold(n_splits)
plot_cv_indices(cv, x, y, groups, axis, n_splits)Producción:
Después de ejecutar el código anterior, obtenemos el siguiente resultado en el que podemos ver que la división de validación cruzada de aprendizaje de scikit se muestra en la pantalla.
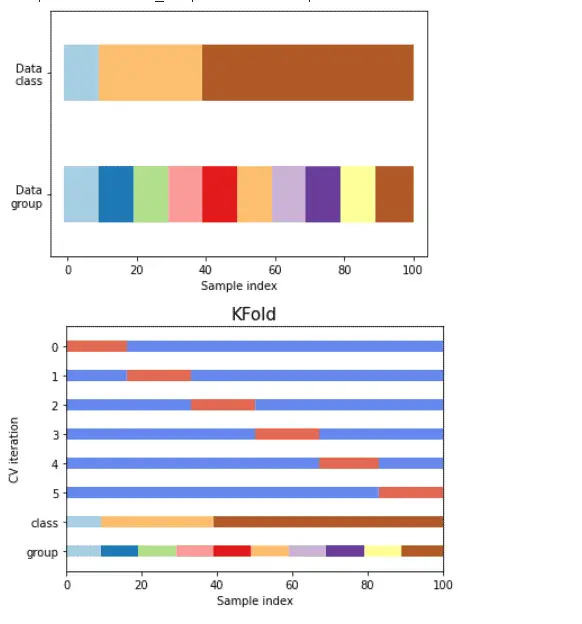 scikit aprender división de validación cruzada
scikit aprender división de validación cruzada
SCIKIT APRENDE MATRIZ DE CONFUSIÓN DE VALIDACIÓN CRUZADA
En esta sección, aprenderemos cómo funciona Scikit Learn Cross-Validation Matrix en Python.
Una matriz de confusión de validación cruzada se define como una matriz de evaluación a partir de la cual podemos estimar el rendimiento del modelo.
Código:
En el siguiente código, importaremos algunas bibliotecas desde las cuales podemos evaluar el rendimiento del modelo.
- iris = datasets.load_iris() se utiliza para cargar los datos del iris.
- print(iris.DESCR) se utiliza para imprimir los datos del iris.
- predicted_targets = num.array([]) se usa para predecir el modelo de valor objetivo.
- actual_targets = num.array([]) se utiliza para obtener el valor objetivo real.
- classifiers = svm.SVC().fit(train_x, train_y) se usa para ajustar el clasificador.
- predicted_labels = classifiers.predict(test_x) se usa para predecir la etiqueta del conjunto de prueba.
import matplotlib.pyplot as plot
import numpy as num
from sklearn import svm, datasets
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import KFold
iris = datasets.load_iris()
data = iris.data
target = iris.target
classnames = iris.target_names
classnames
labels, counts = num.unique(target, return_counts=True)
print(iris.DESCR)
def evaluate_model(data_x, data_y):
k_fold = KFold(10, shuffle=True, random_state=1)
predicted_targets = num.array([])
actual_targets = num.array([])
for train_ix, test_ix in k_fold.split(data_x):
train_x, train_y, test_x, test_y = data_x[train_ix], data_y[train_ix], data_x[test_ix], data_y[test_ix]
classifiers = svm.SVC().fit(train_x, train_y)
predicted_labels = classifiers.predict(test_x)
predicted_targets = num.append(predicted_targets, predicted_labels)
actual_targets = num.append(actual_targets, test_y)
return predicted_targets, actual_targets
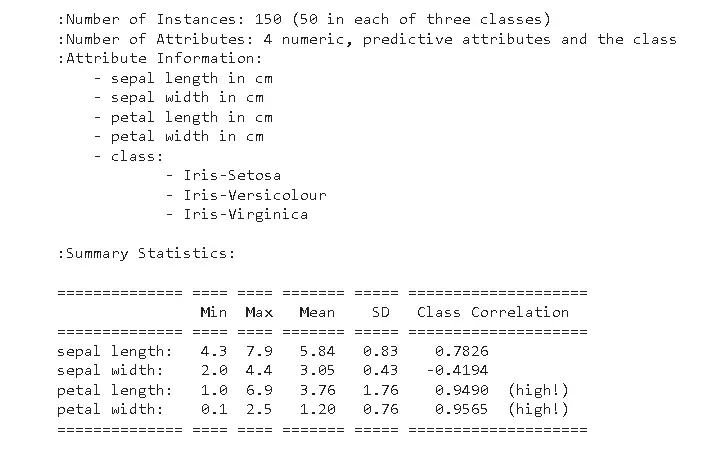 scikit aprender datos de matriz de confusión de validación cruzada
scikit aprender datos de matriz de confusión de validación cruzada
En esta parte del código, generaremos la matriz de confusión normalizada.
- plot.imshow(cnf_matrix, interpolation=’nearest’, cmap=plt.get_cmap(‘Blues’)) se utiliza para trazar la matriz.
- plot.title(title) se utiliza para trazar el título en el gráfico.
- plot.xticks(tick_marks, clases, rotación=45) se usa para trazar los x ticks.
- plot.ylabel(‘Etiqueta verdadera’) se usa para trazar la etiqueta en el gráfico.
- plot.xlabel(‘Etiqueta predicha’) se usa para trazar la etiqueta x en el gráfico.
- plot_confusion_matrix(predicted_target, real_target) se utiliza para trazar la matriz de confusión en la pantalla.
def plot_confusion_matrix(predicted_labels_list, y_test_list):
cnf_matrix = confusion_matrix(y_test_list, predicted_labels_list)
num.set_printoptions(precision=2)
plot.figure()
generate_confusion_matrix(cnf_matrix, classes=class_names, normalize=True, title="Normalized confusion matrix")
plot.show()
def generate_confusion_matrix(cnf_matrix, classes, normalize=False, title="Confusion matrix"):
if normalize:
cnf_matrix = cnf_matrix.astype('float') / cnf_matrix.sum(axis=1)[:, num.newaxis]
print("Normalized confusion matrix")
else:
print('Confusion matrix, without normalization')
plot.imshow(cnf_matrix, interpolation='nearest', cmap=plt.get_cmap('Blues'))
plot.title(title)
plot.colorbar()
tick_marks = np.arange(len(classes))
plot.xticks(tick_marks, classes, rotation=45)
plot.yticks(tick_marks, classes)
fmt=".2f" if normalize else 'd'
thresh = cnf_matrix.max() / 2.
for i, j in itertools.product(range(cnf_matrix.shape[0]), range(cnf_matrix.shape[1])):
plot.text(j, i, format(cnf_matrix[i, j], fmt), horizontalalignment="center",
color="black" if cnf_matrix[i, j] > thresh else "blue")
plot.tight_layout()
plot.ylabel('True label')
plot.xlabel('Predicted label')
return cnf_matrix
predicted_target, actual_target = evaluate_model(data, target)
plot_confusion_matrix(predicted_target, actual_target)Después de ejecutar el código anterior, obtenemos el siguiente resultado en el que podemos ver que la matriz de confusión se traza en la pantalla,
 scikit aprender matriz de confusión de validación cruzada
scikit aprender matriz de confusión de validación cruzada
SCIKIT APRENDE UN HIPERPARÁMETRO DE VALIDACIÓN CRUZADA
En esta sección, aprenderemos sobre Scikit, aprenderemos cómo funcionan los hiperparámetros de validación cruzada en python.
Un hiperparámetro de validación cruzada se define como un proceso que se utiliza para buscar la arquitectura del modelo ideal y también se utiliza para evaluar el rendimiento de un modelo.
Código:
En el siguiente código, importaremos algunas bibliotecas desde las cuales podemos buscar la arquitectura del modelo ideal.
- paramgrid = {‘max_depth’: [4, 5, 10],’min_samples_split’: [3, 5, 10]} se usa para definir la cuadrícula de parámetros.
- x, y = make_classification(n_samples=1000, random_state=0) se usa para hacer la clasificación.
- base_estimator = SVC(gamma=’scale’) se utiliza para definir el estimador base.
- sh = HalvingGridSearchCV(base_estimator, paramgrid, cv=5,factor=2, max_resources=40,aggressive_elimination=True,).fit(x, y) se usa para ajustar el modelo.
from sklearn.datasets import make_classification
from sklearn.ensemble import RandomForestClassifier
from sklearn.experimental import enable_halving_search_cv
from sklearn.model_selection import HalvingGridSearchCV
import pandas as pd
paramgrid = {'max_depth': [4, 5, 10],
'min_samples_split': [3, 5, 10]}
base_estimator = RandomForestClassifier(random_state=0)
x, y = make_classification(n_samples=1000, random_state=0)
sh = HalvingGridSearchCV(base_estimator, paramgrid, cv=6,
factor=2, resource="n_estimators",
max_resources=30).fit(x, y)
sh.best_estimator_
RandomForestClassifier(max_depth=5, n_estimators=24, random_state=0)
from sklearn.datasets import make_classification
from sklearn.svm import SVC
from sklearn.experimental import enable_halving_search_cv
from sklearn.model_selection import HalvingGridSearchCV
import pandas as pds
paramgrid= {'kernel': ('linear', 'rbf'),
'C': [2, 10, 100]}
base_estimator = SVC(gamma="scale")
x, y = make_classification(n_samples=1000)
sh = HalvingGridSearchCV(base_estimator, paramgrid, cv=6,
factor=2, min_resources=20).fit(x, y)
sh.n_resources_
sh = HalvingGridSearchCV(base_estimator, paramgrid, cv=5,
factor=2, min_resources="exhaust").fit(x, y)
sh.n_resources_
from sklearn.datasets import make_classification
from sklearn.svm import SVC
from sklearn.experimental import enable_halving_search_cv
from sklearn.model_selection import HalvingGridSearchCV
import pandas as pds
paramgrid = {'kernel': ('linear', 'rbf'),
'C': [2, 10, 100]}
base_estimator = SVC(gamma="scale")
x, y = make_classification(n_samples=1000)
sh = HalvingGridSearchCV(base_estimator, paramgrid, cv=6,
factor=2, max_resources=40,
aggressive_elimination=False).fit(x, y)
sh.n_resources_
sh = HalvingGridSearchCV(base_estimator, paramgrid, cv=5,
factor=2,
max_resources=40,
aggressive_elimination=True,
).fit(x, y)
sh.n_resources_Producción:
En el siguiente resultado, podemos ver que Scikit aprende un hiperparámetro de validación cruzada que selecciona el modelo ideal que se muestra en la pantalla.
 Scikit aprende un hiperparámetro de validación cruzada
Scikit aprende un hiperparámetro de validación cruzada
SCIKIT APRENDE EL ORDEN ALEATORIO DE VALIDACIÓN CRUZADA
En esta sección, aprenderemos acerca de scikit aprender a mezclar validaciones cruzadas funciona en python.
El barajado de validación cruzada se define como que el usuario genera el tren y la división de prueba, primero se barajan las muestras de datos y luego se dividen en el tren y el conjunto de prueba.
Código:
En el siguiente código, aprenderemos a importar algunas bibliotecas desde las que podemos mezclar los datos y luego dividirlos en entrenar y probar.
- x = num.array([[1, 2], [3, 4], [1, 2], [3, 4]]) se utiliza para generar una matriz.
- kf = KFold(n_splits=2) se utiliza para dividir los datos.
- print(“TREN:”, train_index, “TEST:”, test_index) se utiliza para imprimir los datos del tren y de la prueba.
import numpy as num
from sklearn.model_selection import KFold
x = num.array([[1, 2], [3, 4], [1, 2], [3, 4]])
y = num.array([1, 2, 3, 4])
kf = KFold(n_splits=2)
kf.get_n_splits(x)
print(kf)
for train_index, test_index in kf.split(x):
print("TRAIN:", train_index, "TEST:", test_index)
x_train, x_test = x[train_index], x[test_index]
y_train, y_test = y[train_index], y[test_index]Producción:
Después de ejecutar el código anterior, obtenemos el siguiente resultado en el que podemos ver que los datos se mezclan después de dividirlos en datos de entrenamiento y prueba.
 scikit aprender aleatoria de validación cruzada
scikit aprender aleatoria de validación cruzada
SCIKIT APRENDE BÚSQUEDA DE CUADRÍCULA DE VALIDACIÓN CRUZADA
En esta sección, aprenderemos cómo funciona la búsqueda de cuadrícula de validación cruzada de Scikit Learn en python.
La búsqueda de cuadrícula de validación cruzada se define como un proceso que selecciona el mejor parámetro para todos los modelos de cuadrícula parametrizados.
Código:
En el siguiente código, importaremos algunas bibliotecas desde las cuales podemos seleccionar el mejor parámetro de la cuadrícula.
- iris = datasets.load_iris() se utiliza para cargar el conjunto de datos de iris.
- parámetros = {‘kernel’:(‘linear’, ‘rbf’), ‘C’:[1, 12]} se utiliza para definir los parámetros.
- classifier.fit(iris.data, iris.target) se utiliza para ajustar el modelo.
- sorted(classifier.cv_results_.keys()) se usa para ordenar el clasificador.
from sklearn import svm, datasets
from sklearn.model_selection import GridSearchCV
iris = datasets.load_iris()
parameters = {'kernel':('linear', 'rbf'), 'C':[1, 12]}
svc = svm.SVC()
classifier = GridSearchCV(svc, parameters)
classifier.fit(iris.data, iris.target)
sorted(classifier.cv_results_.keys())Producción:
En el siguiente resultado, podemos ver que el mejor parámetro se muestra en la pantalla que se busca desde la cuadrícula de parámetros.
 scikit aprender búsqueda de cuadrícula de validación cruzada
scikit aprender búsqueda de cuadrícula de validación cruzada