Scikit aprende no lineal [Guía completa]
En este tutorial de Python, aprenderemos cómo funciona Scikit learn non-linear y también cubriremos diferentes ejemplos relacionados con Scikit learn non-linear . Además, cubriremos estos temas.
SCIKIT APRENDE NO LINEAL
En esta sección, aprenderemos cómo funciona Scikit Learn Non-Lineal en Python.
Código:
En el siguiente código, importaremos algunas bibliotecas a partir de las cuales podemos crear la no linealidad de scikit learn.
- x = num.sort(5 * num.random.rand(42, 1), axis=0) se usa para generar los mismos datos.
- y[::5] += 3 * (0.5 – num.random.rand(9)) se usa para agregar el ruido a los objetivos.
- svrrbf = SVR(kernel=”rbf”, C=100, gamma=0.1, epsilon=0.1) para ello se utiliza el modelo de regresión.
- lw = 2 se usa para ver el resultado.
- fig, axes = plot.subplots(nrows=1, ncols=3, figsize=(15, 10), sharey=True) se usa para trazar la figura y el eje en la pantalla.
- ejes[ix].plot(x,svr.fit(x,y).predict(x),color=model_color[ix],lw=lw,label{}model”.format(kernel_label[ix]),) es se utiliza para trazar el eje en la pantalla.
- ejes[ix].scatter(x[svr.support_],y[svr.support_],facecolor=”none”,edgecolor=model_color[ix],s=50,label=”{} vectores de soporte”.format(kernel_label [ix]),) se utiliza para trazar el diagrama de dispersión en la pantalla.
- fig.text(0.5, 0.04, “data”, ha=”center”, va=”center”) se usa para enviar mensajes de texto a figuras.
import numpy as num
from sklearn.svm import SVR
import matplotlib.pyplot as plot
x = num.sort(5 * num.random.rand(42, 1), axis=0)
y = num.sin(x).ravel()
y[::5] += 3 * (0.5 - num.random.rand(9))
svrrbf = SVR(kernel="rbf", C=100, gamma=0.1, epsilon=0.1)
lw = 2
svrs = [svrrbf]
kernel_label = ["RBF"]
model_color = ["m"]
fig, axes = plot.subplots(nrows=1, ncols=3, figsize=(15, 10), sharey=True)
for ix, svr in enumerate(svrs):
axes[ix].plot(
x,
svr.fit(x, y).predict(x),
color=model_color[ix],
lw=lw,
label="{} model".format(kernel_label[ix]),
)
axes[ix].scatter(
x[svr.support_],
y[svr.support_],
facecolor="none",
edgecolor=model_color[ix],
s=50,
label="{} support vectors".format(kernel_label[ix]),
)
axes[ix].scatter(
x[num.setdiff1d(num.arange(len(x)), svr.support_)],
y[num.setdiff1d(num.arange(len(x)), svr.support_)],
facecolor="none",
edgecolor="r",
s=50,
label="other training data",
)
fig.text(0.5, 0.04, "data", ha="center", va="center")
fig.text(0.06, 0.5, "target", ha="center", va="center", rotation="vertical")
plot.show()Producción:
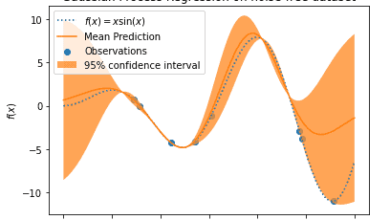
Después de ejecutar el código anterior, obtenemos el siguiente resultado en el que podemos ver que los datos no lineales se muestran en la pantalla.Scikit aprende no lineal
SCIKIT APRENDE REGRESIÓN NO LINEAL
En esta sección, aprenderemos cómo Scikit aprende la regresión no lineal en python.
- La regresión se define como una técnica de aprendizaje automático supervisado. Hay dos tipos de algoritmos de regresión Lineal y no lineal.
- Aquí podemos usar la técnica de regresión no lineal que se usa para describir la no linealidad y su parámetro dependiendo de una o más variables independientes.
Código:
En el siguiente código, aprenderemos algunas bibliotecas a partir de las cuales podemos crear un modelo de regresión no lineal.
- df = pds.read_csv(“regressionchina_gdp.csv”) se usa para leer el archivo que estamos importando.
- plot.figure(figsize=(8,5)) se usa para trazar la figura.
- x_data, y_data = (df[“Año”].valores, df[“Valor”].valores) se utiliza para describir los valores y años.
- plot.plot(x_data, y_data, ‘ro’) se usa para trazar los datos x y los datos y.
- plot.ylabel(‘GDP’) se usa para trazar la etiqueta y.
- plot.xlabel(‘Year’) se usa para trazar la etiqueta x.
import numpy as num
import pandas as pds
import matplotlib.pyplot as plot
df = pds.read_csv("regressionchina_gdp.csv")
df.head(10)
plot.figure(figsize=(8,5))
x_data, y_data = (df["Year"].values, df["Value"].values)
plot.plot(x_data, y_data, 'ro')
plot.ylabel('GDP')
plot.xlabel('Year')
plot.show()scikit aprender regresión no lineal
En el siguiente código, elegimos un modelo para dibujar una regresión lineal en la pantalla.
- plot.plot(x,y) se usa para trazar x e y en la pantalla.
- plot.ylabel(‘Variable dependiente’) se utiliza para trazar la etiqueta y en la pantalla.
- plot.xlabel(‘Variable independiente’) se utiliza para trazar la etiqueta x en la pantalla.
x = np.arange(-5.0, 5.0, 0.1)
y = 1.0 / (1.0 + np.exp(-x))
plot.plot(x,y)
plot.ylabel('Dependent Variable')
plot.xlabel('Indepdendent Variable')
plot.show() scikit aprende regresión no lineal eligiendo un modelo
scikit aprende regresión no lineal eligiendo un modelo
Aquí, podemos usar la función logística para construir nuestro modelo no lineal.
Ahora, plot.plot(x_data, Y_pred*15000000000000.) se usa para trazar la posición inicial contra los puntos de datos.
def sigmoid(x, Beta_1, Beta_2):
y = 1 / (1 + np.exp(-Beta_1*(x-Beta_2)))
return y
beta1 = 0.10
beta2 = 1990.0
#logistic function
Y_pred = sigmoid(x_data, beta1 , beta2)
plot.plot(x_data, Y_pred*15000000000000.)
plot.plot(x_data, y_data, 'ro') scikit aprende regresión no lineal construyendo un modelo
scikit aprende regresión no lineal construyendo un modelo
Aquí podemos normalizar nuestros datos para hacer el mejor ajuste de la curva.
- plot.figure(figsize=(8,5)) se utiliza para trazar la figura en la pantalla.
- plot.plot(xdata, ydata, ‘ro’, label=’data’) se usa para trazar los datos y y los datos x en la pantalla.
- plot.plot(x,y, linewidth=3.0, label=’fit’) se usa para trazar la línea de ajuste en la pantalla.
xdata =x_data/max(x_data)
ydata =y_data/max(y_data)
from scipy.optimize import curve_fit
popt, pcov = curve_fit(sigmoid, xdata, ydata)
# Now we plot our resulting regression model.
x = np.linspace(1960, 2015, 55)
x = x/max(x)
plot.figure(figsize=(8,5))
y = sigmoid(x, *popt)
plot.plot(xdata, ydata, 'ro', label="data")
plot.plot(x,y, linewidth=3.0, label="fit")
plot.legend(loc="best")
plot.ylabel('GDP')
plot.xlabel('Year')
plot.show()Después de ejecutar el código anterior, obtenemos el siguiente resultado en el que podemos ver que la línea de mejor ajuste no lineal se traza en la pantalla.
 scikit aprende el parámetro de mejor ajuste de regresión no lineal
scikit aprende el parámetro de mejor ajuste de regresión no lineal
SCIKIT APRENDE EJEMPLO DE REGRESIÓN NO LINEAL
En esta sección, aprenderemos cómo funciona Scikit aprender el ejemplo de regresión no lineal en python.
La regresión no lineal se define como una regresión cuadrática que construye una relación entre variables dependientes e independientes. Estos datos se muestran mediante una línea curva.
Código:
En el siguiente código, importaremos algunas bibliotecas mediante las cuales funciona un ejemplo de regresión no lineal.
- df = pds.read_csv(“regressionchina_gdp.csv”) se usa para leer el archivo csv que estamos cargando.
- y = 1 / (1 + np.exp(-Beta_1*(x-Beta_2))) se usa para definir una función sigmoidea.
- ypred = sigmoid(x_data, beta1, beta2) se utiliza como función logística.
- plot.plot(x_data, ypred * 16000000000000.) se usa para trazar la predicción inicial contra los puntos de datos.
- plot.plot(x_data, y_data, ‘go’) se usa para trazar x_data e y_data en el gráfico.
import numpy as num
import pandas as pds
import matplotlib.pyplot as plot
df = pds.read_csv("regressionchina_gdp.csv")
def sigmoid(x, Beta_1, Beta_2):
y = 1 / (1 + np.exp(-Beta_1*(x-Beta_2)))
return y
beta1 = 0.10
beta2 = 1990.0
ypred = sigmoid(x_data, beta1, beta2)
plot.plot(x_data, ypred * 16000000000000.)
plot.plot(x_data, y_data, 'go')Producción:
Después de ejecutar el código anterior, obtenemos el siguiente resultado en el que podemos ver que la línea de la curva muestra la no linealidad del gráfico.
 scikit aprender ejemplo de regresión no lineal
scikit aprender ejemplo de regresión no lineal
SCIKIT APRENDE SVM NO LINEAL
En esta sección, aprenderemos cómo funciona scikit learn SVM no lineal en python.
- SVM no lineal significa máquina de vector de soporte, que es un algoritmo de aprendizaje automático supervisado que se utiliza como clasificación y regresión.
- Como sabemos, no lineal se define como una relación entre la variable dependiente e independiente y forma una línea curva para describir el modelo.
Código:
En el siguiente código, importaremos algunas bibliotecas a partir de las cuales podemos crear un modelo SVM no lineal.
- x = num.random.randn(350, 2) se usa para generar los números aleatorios.
- classifier = svm.NuSVC() se usa para hacer el clasificador svm
- classifier.fit(x, Y) se usa para ajustar el modelo.
- Z = classifier.decision_function(np.c_[xx.ravel(), yy.ravel()]) se usa para trazar la función de decisión de cada punto de datos en la cuadrícula.
- plot.imshow(Z, interpolación=’más cercano’, extensión=(xx.min(), xx.max(), yy.min(), yy.max()), aspecto=’auto’,origen=’inferior ‘, cmap=plot.cm.PuOr_r) se utiliza para trazar el gráfico en la pantalla.
- plot.scatter(x[:, 0], x[:, 1], s=35, c=Y, cmap=plot.cm.Paired) se utiliza para trazar el punto de dispersión en la cuadrícula.
import numpy as num
import matplotlib.pyplot as plot
from sklearn import svm
xx, yy = num.meshgrid(num.linspace(-3, 3, 500),
num.linspace(-3, 3, 500))
num.random.seed(0)
x = num.random.randn(350, 2)
Y = num.logical_xor(x[:, 0] > 0, x[:, 1] > 0)
classifier = svm.NuSVC()
classifier.fit(x, Y)
Z = classifier.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plot.imshow(Z, interpolation='nearest',
extent=(xx.min(), xx.max(), yy.min(), yy.max()), aspect="auto",
origin='lower', cmap=plot.cm.PuOr_r)
contours = plot.contour(xx, yy, Z, levels=[0], linewidths=2,
linetypes="--")
plot.scatter(x[:, 0], x[:, 1], s=35, c=Y, cmap=plot.cm.Paired)
plot.xticks(())
plot.yticks(())
plot.axis([-3, 3, -3, 3])
plot.show()Producción:
Después de ejecutar el código anterior, obtenemos el siguiente resultado en el que podemos ver que el gráfico SVM no lineal de aprendizaje de Scikit se traza en la pantalla.
 scikit aprende SVM no lineal
scikit aprende SVM no lineal
SCIKIT APRENDE MODELO NO LINEAL
En esta sección, aprenderemos cómo funciona el modelo no lineal de aprendizaje de Scikit en python.
- El modelo no lineal define la relación no lineal entre los datos y su parámetro dependiendo de una o más variables independientes.
- La no linealidad se muestra donde el punto de datos hace una línea curva a partir de esto se prueba la no linealidad de los datos.
Código:
En el siguiente código, importaremos algunas bibliotecas desde las que podemos ver que el modelo no lineal funciona.
- range = num.random.RandomState(0) se usa para generar el estado aleatorio.
- lendata = (datamax – datamin) se utiliza para obtener la longitud de los datos.
- data = num.sort(range.rand(nsample) * lendata – lendata / 2) se usa para ordenar los datos y hacer que el trazado sea más claro.
- objetivo = datos ** 3 – 0,6 * datos ** 2 + ruido se utiliza para hacer el objetivo.
- full_data = pds.DataFrame({«característica de entrada»: datos, «objetivo»: objetivo}) se utiliza para obtener los datos completos del marco de datos.
- nonlineardata = sns.scatterplot(data=full_data, x=”input feature”, y=”target”, color=”blue”, alpha=0.5) se utiliza para trazar los puntos de dispersión en el gráfico.
import numpy as num
range = num.random.RandomState(0)
nsample = 100
datamax, datamin = 1.5, -1.5
lendata = (datamax - datamin)
data = num.sort(range.rand(nsample) * lendata - lendata / 2)
noise = range.randn(nsample) * .3
target = data ** 3 - 0.6 * data ** 2 + noise
import pandas as pds
full_data = pds.DataFrame({"input feature": data, "target": target})
import seaborn as sns
nonlineardata = sns.scatterplot(data=full_data, x="input feature", y="target",
color="blue", alpha=0.5)Producción:
Después de ejecutar el código anterior, obtenemos el siguiente resultado en el que podemos ver que el modelo no lineal de aprendizaje de Scikit se traza en la pantalla.
 Scikit aprende modelo no lineal
Scikit aprende modelo no lineal
SCIKIT APRENDE UN CLASIFICADOR NO LINEAL
En esta sección, aprenderemos cómo funciona un clasificador no lineal Scikit Learn en python.
El clasificador no lineal se define como un proceso de clasificación que se utiliza para describir la no linealidad y su parámetro en función de una o más variables independientes.
código:
En el siguiente código, importaremos algunas bibliotecas a partir de las cuales podemos crear un clasificador no lineal.
- x = x.copy() se usa para copiar los datos.
- x = num.random.normal(size=(n, 2)) se utiliza para generar los números aleatorios.
- xtrain, xtest, ytrain, ytest = train_test_split(x, y, random_state=0, test_size=0.5) se usa para dividir el conjunto de datos en datos de entrenamiento y datos de prueba.
- plot.figure(figsize=(5,5)) se utiliza para trazar la figura en la pantalla.
- plot.scatter(xtrain[:,0], xtrain[:,1], c=ytrain, edgecolors=’r’); se utiliza para trazar el gráfico de dispersión en la pantalla.
import numpy as num
import matplotlib.pyplot as plot
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
%config InlineBackend.figure_format="svg"
plot.style.use('bmh')
plot.rcParams['image.cmap'] = 'Paired_r'
num.random.seed(5)
def f(x):
x = x.copy()
x[:,0] -= 0.4
x[:,1] += 0.2
return 1.1*x[:,0]**2 + 0.3*x[:,1]**2 - 0.6*x[:,0]*x[:,1]
def makedata():
n = 800
x = num.random.normal(size=(n, 2))
y = f(x) < 0.5
x += num.random.normal(size=(n,2), scale=0.2)
return x, y
x, y = makedata()
xtrain, xtest, ytrain, ytest = train_test_split(x, y, random_state=0, test_size=0.5)
plot.figure(figsize=(5,5))
plot.scatter(xtrain[:,0], xtrain[:,1], c=ytrain, edgecolors="r"); scikit aprende un clasificador no lineal
scikit aprende un clasificador no lineal
En el siguiente código trazaremos los límites del clasificador.
- xx, yy = num.meshgrid(num.arange(x_min, x_max, h),num.arange(y_min, y_max, h)) se utiliza para crear la malla en la pantalla.
- Z = classifier.predict(num.c_[xx.ravel(), yy.ravel()]) se usa para predecir el clasificador.
- plot.figure(figsize=(5,5)) se usa para trazar el clasificador en la pantalla.
- plot.scatter(X[:,0], X[:,1], c=Y, edgecolors=’r’); se utiliza para trazar el gráfico de dispersión en la pantalla.
- plot_boundary(classifier, xtrain, ytrain) se utiliza para trazar los límites del clasificador.
- precision_score(ytest, classifier.predict(xtest)) se utiliza para predecir la puntuación de precisión.
def plot_boundary(classifier, X, Y):
h = 0.02
x_min, x_max = X[:,0].min() - 10*h, X[:,0].max() + 10*h
y_min, y_max = X[:,1].min() - 10*h, X[:,1].max() + 10*h
xx, yy = num.meshgrid(num.arange(x_min, x_max, h),
num.arange(y_min, y_max, h))
Z = classifier.predict(num.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plot.figure(figsize=(5,5))
plot.contourf(xx, yy, Z, alpha=0.25)
plot.contour(xx, yy, Z, colors="r", linewidths=0.7)
plot.scatter(X[:,0], X[:,1], c=Y, edgecolors="r");
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression().fit(xtrain, ytrain)
plot_boundary(classifier, xtrain, ytrain)
accuracy_score(ytest, classifier.predict(xtest)) scikit aprende el límite del clasificador no lineal
scikit aprende el límite del clasificador no lineal
SCIKIT APRENDE REDUCCIÓN DE DIMENSIONALIDAD NO LINEAL
En esta sección, aprenderemos cómo Scikit aprende la reducción de dimensionalidad no lineal que funciona en python.
La reducción de dimensionalidad no lineal se utiliza para reducir la cantidad de elementos en el conjunto de datos sin ninguna pérdida de información.
código:
En el siguiente código, importaremos algunas bibliotecas a partir de las cuales podemos crear una reducción de dimensionalidad no lineal de Scikit Learn.
- advertencias.filterwarnings(‘ignorar’) se utiliza para dar la advertencia de filtro.
- x, y = make_s_curve(n_samples=100) se usa para hacer la curva.
- digits = load_digits(n_class=6) se utiliza para cargar el dígito.
- plot.figure(figsize=(12,8)) se utiliza para trazar la figura en la pantalla.
- axis = plot.axes(projection=’3d’) se utiliza para trazar los ejes en la pantalla.
- axis.scatter3D(x[:, 0], x[:, 1], x[:, 2], c=y) se utiliza para trazar la dispersión en el gráfico.
import sklearn
import numpy as num
import pandas as pds
import matplotlib.pyplot as plot
from mpl_toolkits.mplot3d import Axes3D
import warnings
import sys
warnings.filterwarnings('ignore')
%matplotlib inline
from sklearn.datasets import make_s_curve
x, y = make_s_curve(n_samples=100)
from sklearn.datasets import load_digits
digits = load_digits(n_class=6)
x_digits, y_digits = digits.data, digits. target
print('Dataset Size : ', x_digits.shape, y_digits.shape)
plot.figure(figsize=(12,8))
axis = plot.axes(projection='3d')
axis.scatter3D(x[:, 0], x[:, 1], x[:, 2], c=y)
axis.view_init(10, -60);Producción:
Después de ejecutar el código anterior, obtenemos el siguiente resultado en el que podemos ver la reducción de la dimensionalidad no lineal.
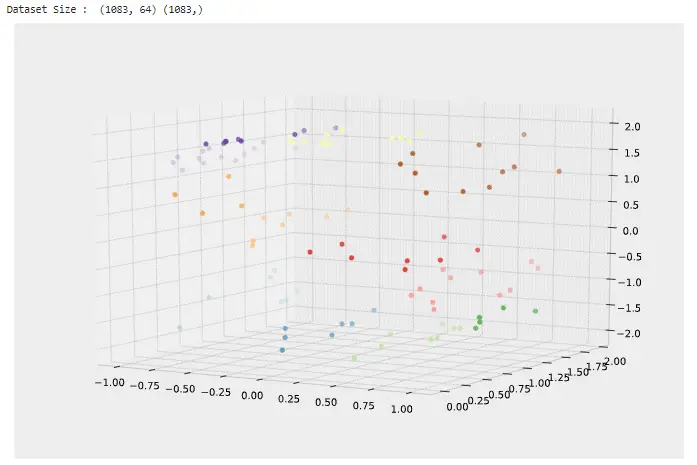 Scikit aprende reducción de dimensionalidad no lineal
Scikit aprende reducción de dimensionalidad no lineal
SCIKIT APRENDE PCA NO LINEAL
En esta sección, aprenderemos cómo Scikit aprende PCA no lineal funciona en python. Donde vamos a mostrar la diferencia entre el PCA y KernalPCA.
- En esto, estamos explicando la diferencia utilizando el ejemplo en el que, por un lado, KernalPCA puede encontrar la proyección de los datos que los separa linealmente, y esto no sucede en el caso de PCA.
- PCA significa Análisis de Componentes Principales. En este proceso, se utiliza en el proceso de los componentes principales. También es el método de reducción de la dimensionalidad el que ayuda a reducir la dimensionalidad.
- Ahora, estamos explicando el ejemplo del PCA no lineal explicando la diferencia entre PCA y KernalPCA utilizando los datos de proyección.
Código:
En el siguiente código, contamos las ventajas de usar el kernel al proyectar datos usando PCA.
En este bloque de código, estamos generando los dos conjuntos de datos anidados.
from sklearn.datasets import make_circles
from sklearn.model_selection import train_test_split
x, y = make_circles(n_samples=1_000, factor=0.3, noise=0.05, random_state=0)
x_train, x_test, y_train, y_test = train_test_split(x, y, stratify=y, random_state=0)
import matplotlib.pyplot as plot
_, (train_ax1, test_ax1) = plot.subplots(ncols=2, sharex=True, sharey=True, figsize=(8, 4))
train_ax1.scatter(x_train[:, 0], x_train[:, 1], c=y_train)
train_ax1.set_ylabel("Feature 1")
train_ax1.set_xlabel("Feature 0")
train_ax1.set_title("Train data")
test_ax1.scatter(x_test[:, 0], x_test[:, 1], c=y_test)
test_ax1.set_xlabel("Feature 0")
_ = test_ax1.set_title("Test data")Producción:
Después de ejecutar el siguiente código, obtenemos el siguiente resultado donde podemos tener una vista rápida de los dos conjuntos de datos generados anidados.
- Uno es el conjunto de datos de entrenamiento y el otro es el conjunto de datos de prueba.
- Las muestras de cada clase no pueden separarse linealmente porque no hay una línea recta que esté separada linealmente a través de la cual pueda dividir el conjunto de datos interno con el conjunto de datos externo.
 Scikit aprende PCA no lineal
Scikit aprende PCA no lineal
En este bloque de código, usamos el PCA con y sin los núcleos para ver qué efectos pueden tener al usar los núcleos.
- El kernel utilizado en esto es el kernel de función de base radial (RBF) .
- orig_data_ax1.set_ylabel() se usa para dar una etiqueta al eje y para los datos de prueba .
- orig_data_ax1.set_xlabel() se usa para dar una etiqueta al eje x para los datos de prueba .
- orig_data_ax1.set_title() se usa para dar una etiqueta al título del gráfico para los datos de prueba .
- pca_proj_ax1.set_ylabel() se usa para dar una etiqueta al eje y para el PCA .
- pca_proj_ax1.set_xlabel() se usa para dar una etiqueta al eje x para el PCA .
- pca_proj_ax1.set_title() se usa para dar el título del gráfico para el PCA .
from sklearn.decomposition import PCA, KernelPCA
pca1 = PCA(n_components=2)
kernel_pca1 = KernelPCA(
n_components=None, kernel="rbf", gamma=10, fit_inverse_transform=True, alpha=0.1
)
x_test_pca1 = pca1.fit(x_train).transform(x_test)
x_test_kernel_pca1 = kernel_pca1.fit(x_train).transform(x_test)
fig, (orig_data_ax1, pca_proj_ax1, kernel_pca_proj_ax1) = plot.subplots(
ncols=3, figsize=(14, 4)
)
orig_data_ax1.scatter(x_test[:, 0], x_test[:, 1], c=y_test)
orig_data_ax1.set_ylabel("Feature 1")
orig_data_ax1.set_xlabel("Feature 0")
orig_data_ax1.set_title("Testing data")
pca_proj_ax1.scatter(x_test_pca1[:, 0], x_test_pca1[:, 1], c=y_test)
pca_proj_ax1.set_ylabel("Principal component 1")
pca_proj_ax1.set_xlabel("Principal component 0")
pca_proj_ax1.set_title("projection of test data\n using PCA")
kernel_pca_proj_ax1.scatter(x_test_kernel_pca1[:, 0], x_test_kernel_pca1[:, 1], c=y_test)
kernel_pca_proj_ax1.set_ylabel("Principal component 1")
kernel_pca_proj_ax1.set_xlabel("Principal component 0")
_ = kernel_pca_proj_ax1.set_title("projection of test data using\n Kernel PCA")Producción:
Después de ejecutar el siguiente código, obtenemos el siguiente resultado donde podemos ver la comparación de los datos de prueba, la proyección de datos de prueba usando PCA y la proyección de datos de prueba usando KernelPCA.
- Revisemos que PCA transforma los datos linealmente, lo que significa que el sistema organizado se centrará, se reajustará en todos los componentes con respecto a su varianza y, finalmente, se rotará.
- Mirando el resultado a continuación, podemos ver en la estructura intermedia que no hay cambios en la estructura relacionada con la escala.
- El kernel PCA permite hacer una proyección no lineal.
- Aquí, al usar un kernel RBF, esperamos que la proyección abra el conjunto de datos mientras se preocupa por mantener las distancias relativas de pares de puntos de datos que están cerca uno del otro en el espacio nativo.
- Podemos ver y observar tales diferencias en la estructura KernelPCA que está en el lado derecho.
 Scikit aprende Kernel PCA no lineal
Scikit aprende Kernel PCA no lineal