Scikit aprende Gaussiano – Todo lo que necesitas saber
En este tutorial de Python, aprenderemos cómo funciona Scikit Learn Gaussian en Python y también cubriremos diferentes ejemplos relacionados con Scikit Learn Gaussian . Y, cubriremos estos temas.
SCIKIT APRENDER GAUSSIANO
En esta sección, aprenderemos cómo funciona Scikit Learn Gaussian en Python.
- Scikit Learn Gaussian es un modelo de aprendizaje automático supervisado. Se utiliza para resolver problemas de regresión y clasificación.
- El proceso gaussiano también se define como un grupo finito de una variable aleatoria que tiene una distribución multivariante.
Código:
En el siguiente código, importaremos algunas bibliotecas desde las cuales podemos resolver el problema de regresión.
- X = num.linspace(start=0, stop=12, num=1_000).reshape(-1, 1) se usa para crear un espacio de línea.
- plot.plot(X, Y, label=r”$f(x) = x \sin(x)$”, linestyle=”dotted”) se utiliza para trazar el gráfico en la pantalla.
- plot.xlabel(“$x$”) se utiliza para trazar el xlabel.
- plot.ylabel(“$f(x)$”) se utiliza para trazar la etiqueta y.
- Gaussian = plot.title(“True Generative Process”) se usa para dar el título al gráfico.
import numpy as num
X = num.linspace(start=0, stop=12, num=1_000).reshape(-1, 1)
Y = num.squeeze(X * num.sin(X))
import matplotlib.pyplot as plot
plot.plot(X, Y, label=r"$f(x) = x \sin(x)$", linestyle="dotted")
plot.legend()
plot.xlabel("$x$")
plot.ylabel("$f(x)$")
Gaussian = plot.title("True Generative Process")Scikit aprende el verdadero proceso generativo gaussiano
- range = num.random.RandomState(1) se utiliza para generar el número aleatorio.
- X_train, Y_train = X[training_indices], Y[training_indices] se utiliza para crear los datos de entrenamiento y prueba.
- gaussianprocess.fit(X_train, Y_train) se usa para ajustar el modelo.
- plot.plot(X, Y, label=r”$f(x) = x \sin(x)$”, linestyle=”dotted” ) se utiliza para trazar el gráfico.
- plot.scatter(X_train, Y_train, label=”Observations”) se usa para trazar el gráfico de dispersión.
- plot.xlabel(“$x$”) se usa para trazar x etiqueta.
- plot.ylabel(“$f(x)$”) se utiliza para trazar la etiqueta y.
- plot.title («Regresión del proceso gaussiano en un conjunto de datos sin ruido») se usa para dar el título al gráfico.
range = num.random.RandomState(1)
training_indices = range.choice(num.arange(Y.size), size=8, replace=False)
X_train, Y_train = X[training_indices], Y[training_indices]
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import RBF
kernel = 1 * RBF(length_scale=1.0, length_scale_bounds=(1e-2, 1e2))
gaussianprocess = GaussianProcessRegressor(kernel=kernel, n_restarts_optimizer=9)
gaussianprocess.fit(X_train, Y_train)
gaussianprocess.kernel_
mean_prediction, std_prediction = gaussian_process.predict(X, return_std=True)
plot.plot(X, Y, label=r"$f(x) = x \sin(x)$", linestyle="dotted")
plot.scatter(X_train, Y_train, label="Observations")
plot.plot(X, mean_prediction, label="Mean Prediction")
plot.fill_between(
X.ravel(),
mean_prediction - 1.98 * std_prediction,
mean_prediction + 1.98 * std_prediction,
alpha=0.7,
label=r"95% confidence interval",
)
plot.legend()
plot.xlabel("$x$")
plot.ylabel("$f(x)$")
Gaussian = plot.title("Gaussian Process Regression on noise-free dataset")Después de ejecutar el código anterior, obtenemos el siguiente resultado en el que podemos ver la regresión del proceso gaussiano en el conjunto de datos sin ruido.
Scikit aprender Gaussiano
SCIKIT APRENDE EL MODELO DE MEZCLA GAUSSIANA
En esta sección, aprenderemos cómo Scikit aprende el modelo de mezcla gaussiana en python.
- Scikit aprende el modelo de mezcla gaussiana se utiliza para definir el proceso que representa la distribución de probabilidad del modelo gaussiano.
- Gaussian Mixture también permite evaluar el parámetro del modelo.
Código:
En el siguiente código, importaremos algunas bibliotecas que representan la distribución de probabilidad del modelo gaussiano.
- num.random.seed(0) se utiliza para generar la muestra aleatoria de dos componentes.
- shiftedgaussian = num.random.randn(n_samples, 2) + num.array([25, 25]) se utiliza para generar datos esféricos.
- stretchedgaussian = num.dot(num.random.randn(n_samples, 2), c) se usa para generar centrado en cero de datos gaussianos estirados.
- X_train = num.vstack([shiftedgaussian, stretchedgaussian]) se usa para concentrar los dos conjuntos de datos en el conjunto de entrenamiento final.
- clasificador = mezcla.GaussianMixture(n_components=2, covariance_type=”full”) se usa para ajustar un modelo de mezcla gaussiana con dos componentes.
- cs=plot.contour(X,Y,Z,norm=LogNorm(vmin=2.0,vmax=1000.0),levels=num.logspace(0, 3, 10) ) se usa para predecir la puntuación como una gráfica de contador.
- plot.scatter(X_train[:, 0], X_train[:, 1], 0.10) se utiliza para trazar el diagrama de dispersión.
- plot.title(“Probabilidad logarítmica negativa predicha por un método de mezcla gaussiana”) se usa para trazar el título en el gráfico.
- plot.axis(“tight”) se utiliza para trazar el eje en el gráfico.
import numpy as num
import matplotlib.pyplot as plot
from matplotlib.colors import LogNorm
from sklearn import mixture
n_samples = 350
num.random.seed(0)
shiftedgaussian = num.random.randn(n_samples, 2) + num.array([25, 25])
c = num.array([[0.0, -0.9], [3.5, 0.9]])
stretchedgaussian = num.dot(num.random.randn(n_samples, 2), c)
X_train = num.vstack([shiftedgaussian, stretchedgaussian])
classifier = mixture.GaussianMixture(n_components=2, covariance_type="full")
classifier.fit(X_train)
x = num.linspace(-25.0, 35.0)
y = num.linspace(-25.0, 45.0)
X, Y = num.meshgrid(x, y)
XX = num.array([X.ravel(), Y.ravel()]).T
Z = -classifier.score_samples(XX)
Z = Z.reshape(X.shape)
cs = plot.contour(
X, Y, Z, norm=LogNorm(vmin=2.0, vmax=1000.0), levels=num.logspace(0, 3, 10)
)
cb = plot.colorbar(cs, shrink=0.10, extend="both")
plot.scatter(X_train[:, 0], X_train[:, 1], 0.10)
plot.title("Negative log-likelihood predicted by a Gaussian Mixture Method")
plot.axis("tight")
plot.show()Producción:
Después de ejecutar el código anterior, obtenemos el siguiente resultado en el que podemos ver que el método de mezcla gaussiana se predica en la pantalla.
 Scikit aprende el modelo de mezcla gaussiana
Scikit aprende el modelo de mezcla gaussiana
SCIKIT APRENDE EL PROCESO GAUSSIANO
En esta sección, aprenderemos cómo funciona Scikit Learn Gaussian Process en Python.
- Scikit aprende que los procesos gaussianos funcionan tanto con la regresión como con la clasificación y con la ayuda de esto aquí podemos crear una estructura de datos discretos.
- La estructura de datos discretos se define como datos en forma discreta.
Código:
En el siguiente código, importaremos algunas bibliotecas a partir de las cuales podemos crear una estructura de datos discretos con la ayuda del proceso gaussiano.
- self.baseline_similarity_bounds=baseline_similarity_bounds se usa para crear los límites de línea base.
- return sum([1.0 if c1 == c2 else self.baseline_similarity for c1 in s1 for c2 in s2]) se usa para devolver el valor del núcleo entre un par de secuencias.
- plot.figure(figsize=(8, 5)) se utiliza para trazar la figura en la pantalla.
- plot.xticks(num.arange(len(X)), X) se usa para trazar las marcas x en el gráfico.
- plot.yticks(num.arange(len(X)), X) se usa para trazar las marcas y en el gráfico.
- plot.title(“Similitud de secuencia bajo el kernel”) se usa para dar el título en la pantalla.
- gaussianprocess = GaussianProcessRegressor(kernel=kernel) se utiliza para procesar el regresor gaussiano.
- gaussianprocess.fit(X[training_idx], Y[training_idx]) se usa para ajustar el modelo.
- plot.bar(num.arange(len(X)), gp.predict(X), color=”r”, label=”prediction”) se utiliza para trazar la barra en la pantalla.
- plot.xticks(num.arange(len(X)), X) se usa para trazar los x ticks.
- plot.title(“Regresión en secuencias”) se usa para dar el título al gráfico.
- gaussianprocess = GaussianProcessClassifier(kernel) se utiliza para procesar el clasificador gaussiano.
- plot.figure(figsize=(8, 5)) se utiliza para trazar la figura en la pantalla.
import numpy as num
import matplotlib.pyplot as plot
from sklearn.gaussian_process.kernels import Kernel, Hyperparameter
from sklearn.gaussian_process.kernels import GenericKernelMixin
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process import GaussianProcessClassifier
from sklearn.base import clone
class SequenceKernel(GenericKernelMixin, Kernel):
def __init__(self, baseline_similarity=0.6, baseline_similarity_bounds=(1e-5, 1)):
self.baseline_similarity = baseline_similarity
self.baseline_similarity_bounds = baseline_similarity_bounds
def hyperparameter_baseline_similarity(self):
return Hyperparameter(
"baseline_similarity", "numeric", self.baseline_similarity_bounds
)
def _f(self, s1, s2):
return sum(
[1.0 if c1 == c2 else self.baseline_similarity for c1 in s1 for c2 in s2]
)
def _g(self, s1, s2)
return sum([0.0 if c1 == c2 else 1.0 for c1 in s1 for c2 in s2])
def __call__(self, X, Y=None, eval_gradient=False):
if Y is None:
Y = X
if eval_gradient:
return (
num.array([[self._f(x, y) for y in Y] for x in X]),
num.array([[[self._g(x, y)] for y in Y] for x in X]),
)
else:
return num.array([[self._f(x, y) for y in Y] for x in X])
def diag(self, X):
return num.array([self._f(x, x) for x in X])
def is_stationary(self):
return False
def clone_with_theta(self, theta):
cloned = clone(self)
cloned.theta = theta
return cloned
kernel = SequenceKernel()
X = num.array(["AGCT", "AGC", "AACT", "TAA", "AAA", "GAACA"])
K = kernel(X)
D = kernel.diag(X)
plot.figure(figsize=(8, 5))
plot.imshow(num.diag(D ** -0.5).dot(K).dot(num.diag(D ** -0.5)))
plot.xticks(num.arange(len(X)), X)
plot.yticks(num.arange(len(X)), X)
plot.title("Sequence similarity Under kernel")
"""
Regression
"""
X = num.array(["AGCT", "AGC", "AACT", "TAA", "AAA", "GAACA"])
Y = num.array([2.0, 2.0, 3.0, 3.0, 4.0, 4.0])
training_idx = [1, 2, 3, 4]
gaussianprocess = GaussianProcessRegressor(kernel=kernel)
gaussianprocess.fit(X[training_idx], Y[training_idx])
plot.figure(figsize=(8, 5))
plot.bar(num.arange(len(X)), gp.predict(X), color="r", label="prediction")
plot.bar(training_idx, Y[training_idx], width=0.2, color="y", alpha=1, label="training")
plot.xticks(num.arange(len(X)), X)
plot.title("Regression On Sequences")
plot.legend()
"""
Classification
"""
X_train = num.array(["AGCT", "CGA", "TAAC", "TCG", "CTTT", "TGCT"])
Y_train = num.array([True, True, True, False, False, False])
gaussianprocess = GaussianProcessClassifier(kernel)
gaussianprocess.fit(X_train, Y_train)
X_test = ["AAA", "ATAG", "CTC", "CT", "C"]
Y_test = [True, True, False, False, False]
plot.figure(figsize=(8, 5))
plot.scatter(
num.arange(len(X_train)),
[1.0 if c else -1.0 for c in Y_train],
s=100,
marker="o",
edgecolor="none",
facecolor=(1, 0.75, 0),
label="training",
)
plot.scatter(
len(X_train) + num.arange(len(X_test)),
[1.0 if c else -1.0 for c in Y_test],
s=100,
marker="o",
edgecolor="none",
facecolor="b",
label="truth",
)
plot.scatter(
len(X_train) + num.arange(len(X_test)),
[1.0 if c else -1.0 for c in gp.predict(X_test)],
s=100,
marker="x",
edgecolor=(0, 2.0, 0.4),
linewidth=2,
label="prediction",
)
plot.xticks(num.arange(len(X_train) + len(X_test)), num.concatenate((X_train, X_test)))
plot.yticks([-1, 1], [False, True])
plot.title("Classification On Sequences")
plot.legend()
plot.show()Producción:
Después de ejecutar el código anterior, obtenemos el siguiente resultado en el que podemos ver que la estructura de datos discreta se dibuja en la pantalla con la ayuda de scikit learn Gaussian process.
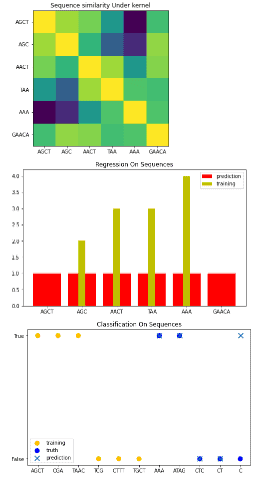 Scikit aprende procesos gaussianos
Scikit aprende procesos gaussianos
SCIKIT APRENDE LA REGRESIÓN GAUSSIANA
En esta sección, aprenderemos cómo funciona Scikit Learn Gaussian Regression en python.
La regresión gaussiana de Scikit Learn se define como un enfoque no paramétrico que crea ondas en la región del aprendizaje automático.
Código:
En el siguiente código, importaremos algunas bibliotecas a partir de las cuales podemos crear un regresor gaussiano.
- x, y = make_friedman2(n_samples=550, noise=0, random_state=0) se usa para hacer Friedman.
- gaussianProcessregression=GaussianProcessRegressor(kernel=kernel,random_state=0).fit(x, y) se usa para crear un regresor gaussiano y ajustar el modelo.
- gaussianProcessregression.score(x, y) se utiliza para contar la puntuación.
from sklearn.datasets import make_friedman2
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import DotProduct, WhiteKernel
x, y = make_friedman2(n_samples=550, noise=0, random_state=0)
kernel = DotProduct() + WhiteKernel()
gaussianProcessregression = GaussianProcessRegressor(kernel=kernel,
random_state=0).fit(x, y)
gaussianProcessregression.score(x, y)Producción:
Después de ejecutar el código anterior, obtenemos el siguiente resultado en el que podemos ver que la puntuación del regresor gaussiano se imprime en la pantalla.
 Scikit aprende el regresor gaussiano
Scikit aprende el regresor gaussiano
SCIKIT APRENDE EL EJEMPLO DE REGRESIÓN GAUSSIANA
En esta sección, aprenderemos sobre Scikit y aprenderemos cómo funciona el ejemplo de regresión gaussiana en python.
- Scikit aprende Gaussian como un grupo finito de una variable aleatoria que tiene una distribución multivariante.
- Scikit aprende La regresión gaussiana se define como un enfoque bayesiano que crea ondas en la región.
Código:
En el siguiente código, importaremos algunas bibliotecas a partir de las cuales podemos crear un gráfico regresor.
- x = num.linspace(0, 7, num=30).reshape(-1, 1) se usa para crear un linspace.
- y = target_generator(x, add_noise=False) se utiliza para crear un generador de destino.
- Gaussianregression= plot.ylabel(“y”) se usa para trazar la etiqueta y en el gráfico.
- range = num.random.RandomState(0) se utiliza para generar el número aleatorio.
- plot.plot(x, y, label=”Señal esperada”) se usa para trazar una señal esperada.
- plot.xlabel(“x”) se utiliza para trazar la etiqueta x.
- gaussianprocessregression = GaussianProcessRegressor(kernel=kernel, alpha=0.0) se usa para crear un regresor gaussiano.
- y_mean, y_std = gaussianprocessregression.predict(x, return_std=True) se utiliza para predecir el modelo.
import numpy as num
def target_generator(x, add_noise=False):
target = 0.7 + num.sin(5 * x)
if add_noise:
range = num.random.RandomState(1)
target += range.normal(0, 0.5, size=target.shape)
return target.squeeze()
x = num.linspace(0, 7, num=30).reshape(-1, 1)
y = target_generator(x, add_noise=False)
import matplotlib.pyplot as plot
Gaussianregression= plot.ylabel("y")
range = num.random.RandomState(0)
x_train = range.uniform(0, 5, size=20).reshape(-1, 1)
y_train = target_generator(x_train, add_noise=True)
plot.plot(x, y, label="Expected signal")
plot.scatter(
x=x_train[:, 0],
y=y_train,
color="red",
alpha=0.4,
label="Observations",
)
plot.legend()
plot.xlabel("x")
Gaussianregression = plot.ylabel("y")
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import RBF, WhiteKernel
kernel = 1.0 * RBF(length_scale=1e1, length_scale_bounds=(1e-2, 1e3)) + WhiteKernel(
noise_level=1, noise_level_bounds=(1e-5, 1e1)
)
gaussianprocessregression = GaussianProcessRegressor(kernel=kernel, alpha=0.0)
gaussianprocessregression.fit(x_train, y_train)
y_mean, y_std = gaussianprocessregression.predict(x, return_std=True)Producción:
Después de ejecutar el código anterior, obtenemos el siguiente resultado en el que podemos ver que el ejemplo del regresor gaussiano se representa en la pantalla.
 Scikit aprende el ejemplo del regresor gaussiano
Scikit aprende el ejemplo del regresor gaussiano
SCIKIT APRENDE GAUSSIAN NAIVE BAYES
En esta sección, aprenderemos cómo funciona scikit learn Gaussian Naive Bayes en python.
- Gaussian Naive Bayes se define como el proceso que admite características de valor continuo.
- Crea un modelo simple y ajusta este modelo simplemente encontrando la media y la desviación estándar de los puntos.
Código:
En el siguiente código, importaremos algunas bibliotecas desde las cuales crear un clasificador Gaussian Naive Bayes.
- n_samples = 50000 se usa para crear n muestras.
- n_bins = 5 el uso de 5 bins para la curva de calibración.
- x, y = make_blobs(n_samples=n_samples, centers=centers, shuffle=False, random_state=42) se usa para generar los 5 blobs y la mitad de los blobs son positivos y la otra mitad son negativos.
- sample_weight = np.random.RandomState(42).rand(y.shape[0]) se utiliza para generar las muestras aleatorias.
- x_train, x_test, y_train, y_test, sw_train, sw_test = train_test_split(x, y, sample_weight, test_size=0.9, random_state=42 ) se usa para dividir el conjunto de datos en datos de entrenamiento y datos de prueba.
- classifier.fit(x_train, y_train) define que el gaussiano no admite pesos de muestra.
- classifier_isotonic = CalibratedClassifierCV(classifier, cv=2, method=”isotonic”) se utiliza para definir bayesianos ingenuos gaussianos con calibración isotónica.
- classifier_sigmoid = CalibratedClassifierCV(classifier, cv=2, method=”sigmoid”) se utiliza para definir bayes ingenuos gaussianos con calibración sigmoidea.
- plot.figure() se utiliza para trazar la figura en la pantalla.
- plot.scatter() se usa para trazar el diagrama de dispersión.
- plot.title(“Data”) se usa para dar el título al gráfico.
import numpy as num
import matplotlib.pyplot as plot
from matplotlib import cm
from sklearn.datasets import make_blobs
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import brier_score_loss
from sklearn.calibration import CalibratedClassifierCV
from sklearn.model_selection import train_test_split
n_samples = 50000
n_bins = 5
centers = [(-7, -7), (0, 0), (7, 7)]
x, y = make_blobs(n_samples=n_samples, centers=centers, shuffle=False, random_state=42)
y[: n_samples // 2] = 0
y[n_samples // 2 :] = 1
sample_weight = np.random.RandomState(42).rand(y.shape[0])
x_train, x_test, y_train, y_test, sw_train, sw_test = train_test_split(
x, y, sample_weight, test_size=0.9, random_state=42
)
classifier = GaussianNB()
classifier.fit(x_train, y_train)
probability_pos_classifier = classifier.predict_proba(x_test)[:, 1]
classifier_isotonic = CalibratedClassifierCV(classifier, cv=2, method="isotonic")
classifier_isotonic.fit(x_train, y_train, sample_weight=sw_train)
probability_pos_isotonic = classifier_isotonic.predict_proba(X_test)[:, 1]
classifier_sigmoid = CalibratedClassifierCV(classifier, cv=2, method="sigmoid")
classifier_sigmoid.fit(x_train, y_train, sample_weight=sw_train)
probability_pos_sigmoid = classifier_sigmoid.predict_proba(x_test)[:, 1]
print("Brier Score Losses: (the smaller the better)")
classifier_score = brier_score_loss(y_test, probability_pos_classifier, sample_weight=sw_test)
print("No Calibration: %1.3f" % clf_score)
classifier_isotonic_score = brier_score_loss(y_test, probability_pos_isotonic, sample_weight=sw_test)
print("With Isotonic Calibration: %1.3f" % classifier_isotonic_score)
classifier_sigmoid_score = brier_score_loss(y_test, probability_pos_sigmoid, sample_weight=sw_test)
print("With Sigmoid Calibration: %1.3f" % classifier_sigmoid_score)
plot.figure()
y_unique = num.unique(y)
colors = cm.rainbow(num.linspace(0.0, 1.0, y_unique.size))
for this_y, color in zip(y_unique, colors):
this_x = x_train[y_train == this_y]
this_sw = sw_train[y_train == this_y]
plot.scatter(
this_x[:, 0],
this_x[:, 1],
s=this_sw * 50,
c=color[num.newaxis, :],
alpha=0.5,
edgecolor="y",
label="Class %s" % this_y,
)
plot.legend(loc="best")
plot.title("Data")
plot.figure()
order = num.lexsort((probability_pos_classifier,))
plot.plot(prob_pos_clf[order], "b", label="No Calibration (%1.3f)" % classifier_score)
plot.plot(
prob_pos_isotonic[order],
"g",
linewidth=3,
label="Isotonic Calibration (%1.3f)" % classifier_isotonic_score,
)
plot.plot(
probability_pos_sigmoid[order],
"y",
linewidth=3,
label="Sigmoid Calibration (%1.3f)" % classifier_sigmoid_score,
)
plot.plot(
num.linspace(0, y_test.size, 51)[1::2],
y_test[order].reshape(25, -1).mean(1),
"r",
linewidth=3,
label=r"Empirical",
)
plot.ylim([-0.05, 1.05])
plot.xlabel("Instances Sorted According to Predicted Probability (uncalibrated GNB)")
plot.ylabel("P(y=1)")
plot.legend(loc="upper left")
plot.title("Gaussian naive Bayes probabilities")
plot.show()Producción:
Después de ejecutar el código anterior, obtenemos el siguiente resultado en el que podemos ver que el gráfico de Bayes ingenuo gaussiano se traza en la pantalla.
 Scikit aprende Gaussian ingenuo Bayes
Scikit aprende Gaussian ingenuo Bayes
SCIKIT APRENDE EL NÚCLEO GAUSSIANO
En esta sección, aprenderemos cómo funciona Scikit Learn Gaussian Kernel en python.
Scikit learn Gaussian kernel se define como un proceso en el que sigma determina el ancho del kernel.
Código:
En el siguiente código, importaremos algunas bibliotecas desde las cuales podemos calcular la puntuación a través del kernel gaussiano.
- x, y = load_iris(return_X_y=True) se utiliza para cargar los datos.
- kernel = 1.0 * RBF(1.0) se usa para calcular el kernel.
- gaussianprocessclassifier = GaussianProcessClassifier(kernel=kernel, random_state=0).fit(x, y) se usa para ajustar el modelo.
- gaussianprocessclassifier.score(x, y) se utiliza para calcular la puntuación.
from sklearn.datasets import load_iris
from sklearn.gaussian_process import GaussianProcessClassifier
from sklearn.gaussian_process.kernels import RBF
x, y = load_iris(return_X_y=True)
kernel = 1.0 * RBF(1.0)
gaussianprocessclassifier = GaussianProcessClassifier(kernel=kernel,
random_state=0).fit(x, y)
gaussianprocessclassifier.score(x, y)Producción:
Después de ejecutar el código anterior, obtenemos el siguiente resultado en el que podemos ver que la puntuación del kernel gaussiano se imprime en la pantalla.
 scikit aprender kernel gaussiano
scikit aprender kernel gaussiano
SCIKIT APRENDE CLASIFICADOR GAUSSIANO
En esta sección, aprenderemos cómo funciona Scikit Learn Gaussian Classifier en Python.
El clasificador gaussiano de Scikit Learn se define como un enfoque productivo que se esfuerza por modelar como una distribución condicional de clase de entrada.
Código:
En el siguiente código, importaremos algunas bibliotecas a partir de las cuales podemos predecir la probabilidad del clasificador gaussiano.
- x, y = load_iris(return_X_y=True) se utiliza para cargar los datos.
- gaussianprocessclassifier = GaussianProcessClassifier(kernel=kernel, random_state=0).fit(x, y) se usa para ajustar el modelo clasificador.
- gaussianclassifier.predict_proba(x[:2,:]) se usa para predecir la probabilidad del clasificador.
from sklearn.datasets import load_iris
from sklearn.gaussian_process import GaussianProcessClassifier
from sklearn.gaussian_process.kernels import RBF
x, y = load_iris(return_X_y=True)
kernel = 1.0 * RBF(1.0)
gaussianclassifier = GaussianProcessClassifier(kernel=kernel,
random_state=0).fit(x, y)
gaussianclassifier.score(x, y)
gaussianclassifier.predict_proba(x[:2,:])Producción:
Después de ejecutar el código anterior, obtenemos el siguiente resultado en el que podemos ver que la probabilidad de un clasificador gaussiano se predice en la pantalla.
![]() Scikit aprende clasificador gaussiano
Scikit aprende clasificador gaussiano
SCIKIT APRENDE EL CLASIFICADOR DE PROCESOS GAUSSIANO
En esta sección, aprenderemos cómo funciona Scikit Learn Gaussian Process Classifier en Python.
El clasificador de procesos gaussianos de Scikit Learn se define como una aproximación de Laplace y un enfoque productivo que admite la clasificación de clases múltiples.
Código:
En el siguiente código, importaremos algunas bibliotecas desde las cuales podemos hacer gráficos con la ayuda de un clasificador de procesos gaussiano.
- iris = datasets.load_iris() se usa para cargar algunos datos de iris.
- X = iris.data[:, :2] se usa para tomar las dos primeras funciones.
- gaussianprocessclassifier_rbf_isotropic=GaussianProcessClassifier(kernel=kernel).fit(X, y) se usa para ajustar el modelo.
- titles = [“Isotropic RBF”, “Anisotropic RBF”] se usa para dar el título al gráfico.
- Z = classifier.predict_proba(num.c_[xx.ravel(), yy.ravel()]) se usa para predecir la probabilidad
- plot.imshow(Z, extension=(x_min, x_max, y_min, y_max), origin=”lower”) se utiliza para trazar el gráfico.
- plot.scatter(X[:, 0], X[:, 1], c=num.array([“y”, “c”, “g”])[y], edgecolors=(0, 0, 0 )) se utiliza para trazar el gráfico de dispersión.
- plot.xlabel(“Longitud del sépalo”) se utiliza para trazar la etiqueta x.
- plot.title(“%s,LML:%.3f(titles[i],classifier.log_marginal_likelihood(classifier.kernel_.theta)) ) se utiliza para trazar el título en el gráfico.
import numpy as num
import matplotlib.pyplot as plot
from sklearn import datasets
from sklearn.gaussian_process import GaussianProcessClassifier
from sklearn.gaussian_process.kernels import RBF
iris = datasets.load_iris()
X = iris.data[:, :2]
y = num.array(iris.target, dtype=int)
h = 0.04
kernel = 1.0 * RBF([1.0])
gaussianprocessclassifier_rbf_isotropic = GaussianProcessClassifier(kernel=kernel).fit(X, y)
kernel = 1.0 * RBF([1.0, 1.0])
gaussianprocessclassifier_rbf_anisotropic = GaussianProcessClassifier(kernel=kernel).fit(X, y)
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = num.meshgrid(num.arange(x_min, x_max, h), num.arange(y_min, y_max, h))
titles = ["Isotropic RBF", "Anisotropic RBF"]
plot.figure(figsize=(12, 7))
for i, classifier in enumerate((gaussianprocessclassifier_rbf_isotropic, gaussianprocessclassifier_rbf_anisotropic)):
plot.subplot(1, 2, i + 1)
Z = classifier.predict_proba(num.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape((xx.shape[0], xx.shape[1], 3))
plot.imshow(Z, extent=(x_min, x_max, y_min, y_max), origin="lower")
plot.scatter(X[:, 0], X[:, 1], c=num.array(["y", "c", "g"])[y], edgecolors=(0, 0, 0))
plot.xlabel("Sepal length")
plot.ylabel("Sepal width")
plot.xlim(xx.min(), xx.max())
plot.ylim(yy.min(), yy.max())
plot.xticks(())
plot.yticks(())
plot.title(
"%s, LML: %.3f" % (titles[i], classifier.log_marginal_likelihood(classifier.kernel_.theta))
)
plot.tight_layout()
plot.show()Producción:
Después de ejecutar el código anterior, obtenemos el siguiente resultado en el que podemos ver que el gráfico del clasificador de procesos gaussiano se traza en la pantalla.
 scikit aprender clasificador de procesos gaussianos
scikit aprender clasificador de procesos gaussianos
SCIKIT APRENDE EL PROCESO GAUSSIANO RBF KERNEL
En esta sección, aprenderemos cómo Scikit aprende el funcionamiento del kernel RBF del proceso gaussiano en python.
Scikit aprende el proceso gaussiano RBF kernel se define como un kernel que es un escalador o que tiene el mismo número de dimensiones.
Código:
En el siguiente código, importaremos algunas bibliotecas desde las cuales podemos hacer un gráfico con la ayuda del kernel RBF.
- x = num.linspace(0, 5, 100) se usa para crear un linspace.
- y_samples = gpr_model.sample_y(X, n_samples) se usa para crear un modelo de muestra.
- axis.plot() se utiliza para trazar el modelo.
- axis.plot(x, y_mean, color=”blue”, label=”Mean”) se utiliza para trazar el eje.
- X_train = range.uniform(0, 5, 10).reshape(-1, 1) se usa para crear el rango uniforme.
- plot_gpr_samples(gaussianprocessregressor, n_samples=n_samples, axis=axs[0]) se utiliza para trazar las muestras.
- axs[0].set_title(“Muestras de distribución anterior”) se utiliza para dar el título al gráfico.
- axs[1].scatter(X_train[:, 0], y_train, color=”red”, zorder=10, label=”Observations”) se utiliza para trazar el diagrama de dispersión.
import matplotlib.pyplot as plot
import numpy as num
def plot_gpr_samples(gpr_model, n_samples, axis):
x = num.linspace(0, 5, 100)
X = x.reshape(-1, 1)
y_mean, y_std = gpr_model.predict(X, return_std=True)
y_samples = gpr_model.sample_y(X, n_samples)
for idx, single_prior in enumerate(y_samples.T):
axis.plot(
x,
single_prior,
linestyle="--",
alpha=0.7,
label=f"Sampled function #{idx + 1}",
)
axis.plot(x, y_mean, color="blue", label="Mean")
axis.fill_between(
x,
y_mean - y_std,
y_mean + y_std,
alpha=0.1,
color="blue",
label=r"$\pm$ 1 std. dev.",
)
axis.set_xlabel("x")
axis.set_ylabel("y")
axis.set_ylim([-3, 3])
range = num.random.RandomState(4)
X_train = range.uniform(0, 5, 10).reshape(-1, 1)
y_train = num.sin((X_train[:, 0] - 2.5) ** 2)
n_samples = 5
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import RBF
kernel = 1.0 * RBF(length_scale=1.0, length_scale_bounds=(1e-1, 10.0))
gaussianprocessregressor = GaussianProcessRegressor(kernel=kernel, random_state=0)
fig, axs = plot.subplots(nrows=2, sharex=True, sharey=True, figsize=(10, 8))
plot_gpr_samples(gaussianprocessregressor, n_samples=n_samples, axis=axs[0])
axs[0].set_title("Samples from prior distribution")
gpr.fit(X_train, y_train)
plot_gpr_samples(gaussianprocessregressor, n_samples=n_samples, axis=axs[1])
axs[1].scatter(X_train[:, 0], y_train, color="red", zorder=10, label="Observations")
axs[1].legend(bbox_to_anchor=(1.05, 1.5), loc="upper left")
axs[1].set_title("Samples from posterior distribution")
fig.suptitle("Radial Basis Function kernel", fontsize=18)
plot.tight_layout()Producción:
Después de ejecutar el código anterior, obtenemos el siguiente resultado en el que podemos ver que el gráfico del kernel RBF del proceso gaussiano de Scikit Learn se traza en la pantalla.
 scikit aprende el kernel RBF del proceso gaussiano
scikit aprende el kernel RBF del proceso gaussiano